
By: Xiang Li, Ankush Khandelwal, Christopher Duffy, Vipin Kumar , John L. Nieber, and Michael Steinbach
In 2016 AlphaGo and its successor programs defeated human Go professionals using AI (artificial intelligence) (AlphaGo, n.d.). AlphaGo was developed to test how well a neural network using deep learning can compete at the game Go and other board games (chess) without being taught the rules. The tremendous growth in “AI,” “machine learning (ML),” and “big data” has declared a new era sometimes called the “fourth industrial revolution,” which has fundamentally changed the way we live and work. For example, customers are targeted with more effective business advertisements. Live captions on the media are more semantically accurate. Behind these scenes is the advent of machine learning.
Although the unreasonably effective predictive performance of ML models may make them appear mysterious to some (Sejnowski, 2020), they are not unintelligible to practitioners. In simplest terms, any applicable ML model can be broken down into three components: general model architecture, purpose-orientated loss function, and an optimization algorithm. (Technically, linear regression is also an ML model.) These components can be customized and re-designed for a specific problem. With appropriate modification, an ML algorithm can be transformed to solve a well-defined problem even for specialized science and engineering domains with data-rich scenarios. This generalizability is a blueprint for ML applications.
Indeed, in the natural sciences, ML is already having an enormous impact, e.g., ML was relevant to thirteen percent of all STEM papers submitted in 2019 (ArXiv Submission Rate Statistics, 2020). The increasing availability of large volumes of scientific data provides unprecedented opportunities for data-centric research. While ML can discover complex patterns in the data, it is quite distinct from the traditional scientific discovery paradigm. Both ML and knowledge-based discovery aim to determine a logical path connecting data to a conclusion. The data-driven pathway may not follow scientific guidelines and usually ignores the wealth of accumulated scientific knowledge. On the other hand, the knowledge-based pathway does not fully leverage the information hidden in data since the scientific processes involved might not comprehensively explain all interesting patterns in data. To bridge this gap between ML and knowledge-based discovery, there is an emerging research direction named “Knowledge Guided Machine Learning” (KGML) that has captured the interest of both academia and industry. In a nutshell, the information behind the data can be transformed into knowledge. With the guidance of scientific knowledge from domain experts, the KGML framework accelerates science discovery processes.
In August 2020, the University of Minnesota Twin Cities held an inaugural 3-day virtual workshop, which engaged worldwide researchers to discuss the KGML framework (1st Workshop on Knowledge Guided Machine Learning (KGML), 2020; 2nd Workshop on Knowledge Guided Machine Learning (KGML), 2021), which engaged researchers worldwide for discussions on the KGML framework. Among the natural science sessions covered in the workshop, one session involved the domain of hydrology. In that session, one of the delivered presentations was how to use KGML to predict basin discharge by incorporating hydrologic knowledge into an ML model. This implementation demonstrated some success at emulating the streamflow mechanism of the well-known hydrologic model, SWAT (Khandelwal et al., 2020). In one small watershed in Southeast Minnesota, the SWAT generated discharge was emulated satisfactorily when the ML model adopted concepts of hydrologic system memories, such as soil moisture and snow accumulation. As shown in Figure 1 (1-year data for visualization), KGML improves streamflow prediction compared to the case when no physics is included in the ML model. Putting those time series data in a scatter plot, it clearly shows that KGML prediction matches with the SWAT synthetic data more consistently. Through the whole testing period, the NSE score improves from 0.57 to 0.76 when implementing KGML.
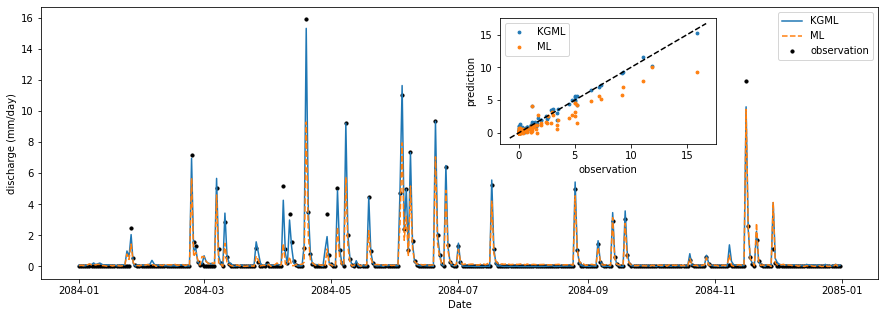
Although still at an early stage, both ML and KGML exhibit their remarkable potential in hydrology. Scientific discovery and the understanding of complex hydrologic systems awaits help from these epoch-making data-driven methods. Considering that the future is bright for data acquisition, especially with the ever-increasing amount of satellite data and inexpensive ground-based data acquisition systems, this bodes well for future applications of ML coupled with physics models. In addition to this result at the KGML2020, broad application successes of ML across domains were also discussed at the workshop, including applications in weather forecasting, lake modeling, and cancer diagnosis. This leads to the question: “When so many disciplines embrace the rise of ML, how should hydrologists adapt to this burgeoning trend in such a short time? ”
The International Association of Scientific Hydrology (IAHS) proposed the dedication in 2003-2012 to “Prediction in Ungauged Basin” (PUB) (Sivapalan et al., 2003). Following that theme, in the next decade (2013-2022), the theme became “Prediction Under Change” (PUC) (Sivapalan, 2011). One traditional approach to modeling hydrologic systems is the physically-based hydrologic model, which predicts watershed responses by lumping hydrological processes into the catchment system. However, the performance of such models is not satisfactory in all basins. As a result, there has been an increasing trend to take advantage of the predictive power of ML in hydrology. ML models outperform physically-based models in some instances, but it should be noted that pure ML models will definitely not replace hydrological models because they rely heavily on data richness. ML is unsuited for the data insufficient basins situation. However, it would make sense to utilize the forecast ability of ML to solve hydrology problems by incorporating principles of hydrology (e.g., conservation of mass, conservation of energy, etc.). Consequently, KGML will be an appropriate candidate approach that implements ML under the guidance of hydrology knowledge, which requires significant collaborative research efforts between data scientists and hydrologists. Coupling physically-based hydrological models and data-driven ML models will be a future research direction for comprehending complicated watershed systems. While interdisciplinary research efforts are continually contributing to model complex hydrological systems with the assistance from ML, it is anticipated that more definitive answers to the PUB and PUC themes will gradually develop within this decade.
References:
1st Workshop on Knowledge Guided Machine Learning (KGML). (2020). University of Minnesota. https://sites.google.com/umn.edu/kgml/
2nd Workshop on Knowledge Guided Machine Learning (KGML). (2021). University of Minnesota. https://sites.google.com/umn.edu/kgmlworkshop/workshop
AlphaGo. (n.d.). Wikipedia. Retrieved June 28, 2021, from https://en.wikipedia.org/wiki/AlphaGo
arXiv submission rate statistics. (2020). Cornell University. https://arxiv.org/help/stats/2019_by_area
Khandelwal, A., Xu, S., Li, X., Jia, X., Stienbach, M., Duffy, C., Nieber, J., & Kumar, V. (2020). Physics Guided Machine Learning Methods for Hydrology. AAAI Symposium.
Sejnowski, T. J. (2020). The unreasonable effectiveness of deep learning in artificial intelligence. Proceedings of the National Academy of Sciences of the United States of America, 117(48), 30033–30038. https://doi.org/10.1073/pnas.1907373117
Sivapalan, M. (2011). Prediction under change (PUC): Water, Earth and Biota in the Anthropocene. AGU Fall Meeting Abstracts, April, 1–64. http://adsabs.harvard.edu/abs/2011AGUFMGC34B..01S
Sivapalan, M., Takeuchi, K., Franks, S. W., Gupta, V. K., Karambiri, H., Lakshmi, V., Liang, X., McDonnell, J. J., Mendiondo, E. M., O’Connell, P. E., Oki, T., Pomeroy, J. W., Schertzer, D., Uhlenbrook, S., & Zehe, E. (2003). IAHS Decade on Predictions in Ungauged Basins (PUB), 2003-2012: Shaping an exciting future for the hydrological sciences. Hydrological Sciences Journal, 48(6), 857–880. https://doi.org/10.1623/hysj.48.6.857.51421
About Authors
Xiang Li is a current PhD candidate in the Water Resources Science program at the University of Minnesota. He has declared a graduate minor in computer science (machine learning and data mining in particular) at UMN. His master thesis is about baseflow recession analysis and groundwater storage change analysis. His current work focuses on integrating machine learning algorithms into hydrology modeling, including SWAT models and classic baseflow recession analysis.

Ankush Khandelwal is a Research Associate in the Computer Science Department at University of Minnesota. He has a PhD in Computer Science from University of Minnesota. Khandelwal’s research has been focused on developing novel machine learning algorithms to analyze vast amounts of satellite imagery for different earth science domains such as water, agriculture and forestry. His current research work is focused on developing physics aware machine learning algorithms for hydrological applications.

John L. Nieber is a native of Upstate New York and he received his B.S. degree in Forest Engineering at Syracuse University in 1972, his M.S. degree in Civil and Environmental Engineering at Cornell University in 1974, and his Ph.D. in Agricultural Engineering at Cornell University in 1979. He is the Full Professor at the University of Minnesota in the Bioproducts and Biosystems Engineering department. John’s research interests involve hydrologic process discovery and modeling, with particular interest in flow and transport processes in porous media. Current research involves studies on utilizing infiltration for stormwater control in urban areas, assessing best management practices impacts on reduction of nitrate in groundwater, combining hydrologic models with machine learning, and quantifying mass and energy transport processes in urban ecosystems.

Christopher Duffy is an Emeritus Professor in the Civil and Environmental Engineering Department of Penn State University. He has held appointments at Los Alamos National lab (1998-99), Cornell University (1987-88), Ecole Polytechnic Lausanne (2006-07), Smithsonian Institution, University Bristol, UK (2014-2016) University of Bonn, DE (2015). Duffy and his team focus on developing spatially-distributed, physics-based computational models for multi-scale, multi-process water resources applications (http://www.pihm.psu.edu/), supported by automated data services (www.hydroterre.psu.edu). Recent research as PI/Co-PI includes: NSF Critical Zone Observatory, NSF INSPIRE, NSF EarthCube, EPA, CNH, DARPA World Modelers and NSF HDR.

Vipin Kumar is a Regents Professor at the University of Minnesota, where he holds the William Norris Endowed Chair in the Department of Computer Science and Engineering. He has authored over 400 research articles, and has coedited or coauthored 10 books including two textbooks “Introduction to Parallel Computing” and “Introduction to Data Mining”, that are used world-wide and have been translated into many languages. Kumar’s current major research focus is on bringing the power of big data and machine learning to understand the impact of human induced changes on the Earth and its environment. Kumar has been elected a Fellow of the American Association for Advancement for Science (AAAS), Association for Computing Machinery (ACM), Institute of Electrical and Electronics Engineers (IEEE), and Society for Industrial and Applied Mathematics (SIAM). Kumar’s foundational research in data mining and high-performance computing has been honored by the ACM SIGKDD 2012 Innovation Award, which is the highest award for technical excellence in the field of Knowledge Discovery and Data Mining (KDD), and the 2016 IEEE Computer Society Sidney Fernbach Award, one of IEEE Computer Society’s highest awards in high-performance computing.

Michael Steinbach earned his B.S. degree in Mathematics, a M.S. degree in Statistics, and M.S. and Ph.D. degrees in Computer Science from the University of Minnesota. He is currently a researcher in the Department of Computer Science and Engineering at the University of Minnesota, Twin Cities working in the research group of Prof. Vipin Kumar. His research interests are in the area of data mining, machine learning, biomedical informatics, and statistics. Dr. Steinbach is a co-author of the data mining textbook, Introduction to Data Mining, published by Addison-Wesley, which is used world-wide and has been translated into many languages. Previously, he held a variety of software engineering, analysis, and design positions in industry at Silicon Biology, Racotek, and NCR.
